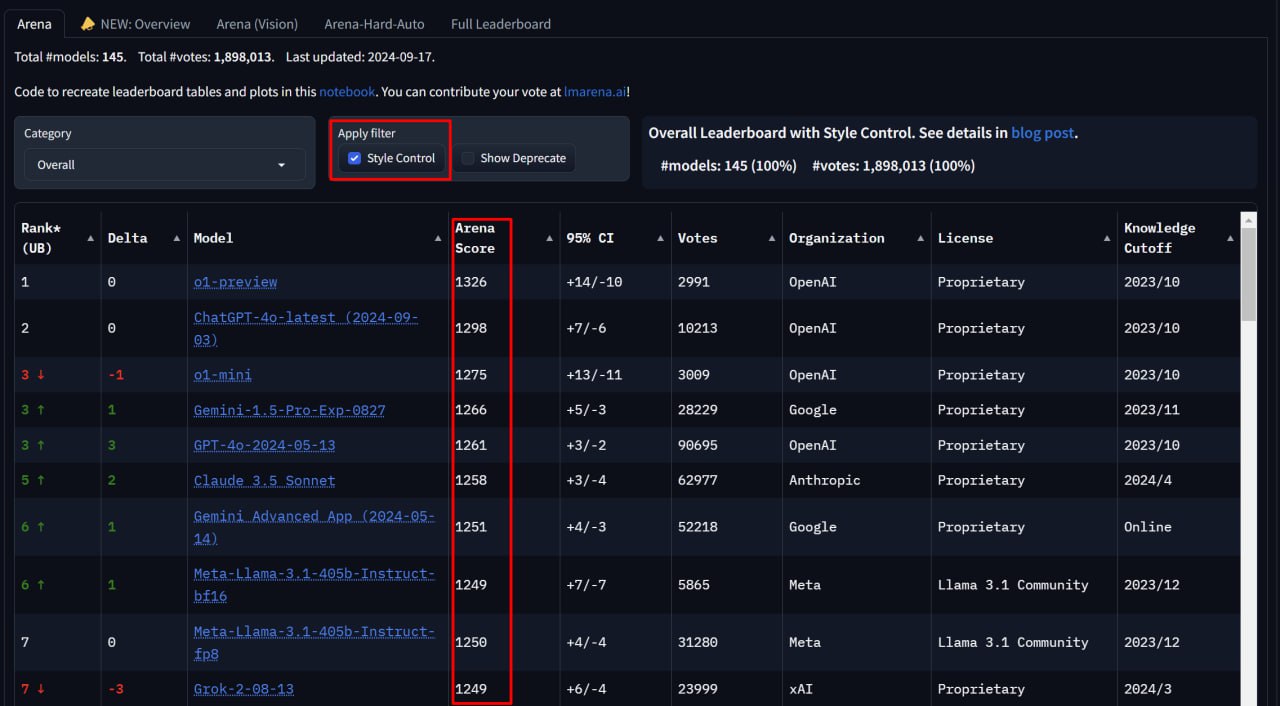
ОДНАКО
Модели всё равно в топе - на первом и третьем месте. И это с учётом контроля по стилю и длине - то есть к рейтингу модели применяют некоторую поправку, которая штрафует за очень длинные ответы, а также те, что содержат много списков, заголовков итд. Детали в официальном блоге тут .
В математике отрывы вообще неприличные (второй скрин).
А ещё обратите внимание, что обновилась модель ChatGPT (это та, которая заточена на диалоги, и именно к ней получают доступ пользователи сайта chatgpt) - она заработала +20 очков относительно предыдущей версии. То есть o1 лучше ChatGPT которая лучше прошлых ChatGPT которые лучше всех остальных моделей.
😦
Источник
Смотреть рейтинги тут
UPD: ещё добавили в сравнение 16-битную версию LLAMA-3.1-405B. Она в рейтинге выше, чем обычная пожатая восьмибитная, что ожидаемо. Разница наибольшая в reasoning-heavy задачах
Пост 18.09.2024 20:57